This Week In SEO 54
New Google Features and Robots.txt
Rich Cards in the SERPs
https://webmasters.googleblog.com/2016/05/introducing-rich-cards.html
It was a big week for Google, with their 2016 I/O conference, and a lot of interesting things have come out.
One of the biggest things (as far as SEO is concerned) is the introduction of rich cards.
WTF is a rich card?
Rich cards are a new Search result format building on the success of rich snippets. Just like rich snippets, rich cards use schema.org structured markup to display content in an even more engaging and visual format, with a focus on providing a better mobile user experience.
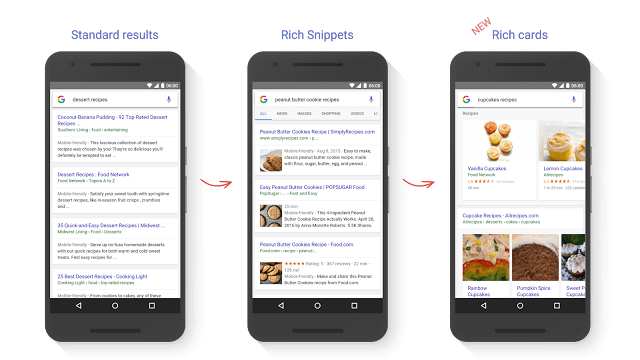
It’s all about that mobile user experience.
If you’ve got a site in the recipe or movie niche, upgrade your Schema game and start experimenting with this new visual-heavy result.
The Google blog has a bunch of helpful links to get you started with these new rich result.
Tie All Your Sites Together in Search Console
https://webmasters.googleblog.com/2016/05/tie-your-sites-together-with-property.html

Your mobile site, your AMP traffic, your app–all can now be treated inside Search Console as one site.
Property Sets will treat all URIs from the properties included as a single presence in the Search Analytics feature. This means that Search Analytics metrics aggregated by host will be aggregated across all properties included in the set. For example, at a glance you’ll get the clicks and impressions of any of the sites in the set for all queries.
This new feature will be rolling out over the few days, so keep an eye out for it if you’ve got some properties that could benefit.
A New Google Search Platform
http://searchengineland.com/google-assistant-249903
Don’t call it a bot, you nerd. This Siri-ish/Cortana-ish/Alex-ish product from Google is not an assistant for you to boss around, but rather an extension of the Google search engine that you interact with using voice.
So what is Google assistant, in the end? Google assistant combines two things: Google’s expertise in extracting information from content across the web and from partners plus its machine learning smarts to understand what people are asking.
Put another way, Google search has been largely a way that people typed queries in a one-way conversation to get information that they themselves used to complete tasks. Google assistant is going beyond that, to a two-way conversation, one that aims to fulfill tasks as well.

Interesting to obsess over until it actually launches and we can see first-hand what kind of impact it will have on the SEO industry. If nothing else, it’s a good reminder to stay up to date and to constantly innovate.
Also, if you’ve been putting off looking into conversational content and optimizing for Hummingbird, now’s a good time to get started…
De-indexed Pages Blocked in Robots.txt
http://ohgm.co.uk/de-index-pages-blocked-robots-txt
Has this ever happened to you?
You specify pages to block from being crawled/indexed, but there the little bots go, crawling and indexing pages you didn’t want crawled or indexing, making a MESS of everything, like

THERE’S GOT TO BE A BETTER WAY!
In this test was a site that hasn’t been accessible to crawl for over two years. I think this makes for a good test – we are removing a particularly stubborn stain here. But because of this I also believe it’s a particularly slow test. The only exposure to those URLs is the ancient memory Google has of them (it can’t access the sitemap or internal links) and the submission to an indexing service.
There’s also the possibility that Google is electing to keep these URLs in the index because of third party signals. Like the links agency types were hitting them with from 2011 to 2013.
So this is a small solution to an infrequent problem, but if you have a URL you are trying to get out of Google’s index, it’s an important solution.
To oversimplify and sum it up: if you tell the Robots.txt file to disallow the URL to be crawled, the URL still has to be crawled to get the information.
The solution here it to swap out “noindex” for “disallow.” The results of the experiment were that a URL that had been “disallowed” via Robots.txt was showing up in Google like this:

Several days later, many of the domains had dropped out of the index.

Yoast on Robots.txt
https://yoast.com/ultimate-guide-robots-txt/
Speaking of robots…
Yoast, the most drawn man in SEO, has released a pretty epic post on all things Robots.txt
This is probably more information than you’ll ever need, but it’s always a good thing to know WHERE that information lives, so when you need it, you know where to find it.
The robots.txt file is one of the primary ways of telling a search engine where it can and can’t go on your website. All major search engines support the basic functionality it offers. There are some extra rules that are used by a few search engines which can be useful too.
This guide covers all the uses of robots.txt for your website. While it looks deceivingly simple, making a mistake in your robots.txt can seriously harm you site, so make sure to read and understand this.
As I always like to point out, this is also a good example of some seriously high-quality, relevant, in-depth content. This page is gonna rank super well for many robot.txt-related searches. Learn from it!






